Global cloud deployments demand routing decisions that respond to real-time network conditions. For SaaS, DevOps, and enterprise teams distributing workloads across AWS, Google Cloud, and Azure, the path a request chooses can be the difference between a sub-50ms experience and an intolerable tail latency. Traditional, static endpoints fall short in this environment, especially when regional outages, cross-cloud link congestion, or sudden traffic surges occur. This article outlines a practical approach to cloud routing optimization - one that blends DNS-based traffic engineering, global routing choices, and domain intelligence to reduce latency and improve uptime. Note: the strategies discussed here are data-driven and testable, with the aim of being implementable within a realistic enterprise footprint.
As you read, consider datasets you might use to stress-test routing strategies. Some teams experiment with curated domain lists to simulate diverse user bases or to validate failover behavior. For example, certain organizations reference datasets such as download list of .pl domains, download list of .cc domains, and related TLD inventories to test DNS resolution performance across geographies. While these lists are just one input among many, they provide a realistic proxy for population diversity and DNS query patterns when evaluating routing choices. And for teams that rely on domain data for validation or enrichment, resources like RDAP & WHOIS database can help ensure you’re working with authoritative, up-to-date records. (cloud.google.com)
What is Cloud Routing Optimization, and why it matters in a multi-cloud world?
Cloud routing optimization is the disciplined practice of selecting network paths, data-center egress points, and DNS directions that collectively minimize latency, reduce jitter, maximize uptime, and respect service-level agreements across suppliers and geographies. In multi-cloud environments, latency can be dominated by regional egress choices, cross-cloud interconnects, and DNS resolution patterns. A robust optimization program treats routing as a control plane: you observe performance, decide on routing policies, and continuously validate those choices under real user traffic conditions. Industry guidance emphasizes resilient interconnects, rapid failover, and smooth transitions to backup paths when faults occur. For example, modern cloud networking best practices advocate enabling fast failover, graceful restart of BGP sessions, and health-aware routing decisions to avoid traffic black-holes during outages. (cloud.google.com)
DNS-based traffic engineering: the control plane you can tune
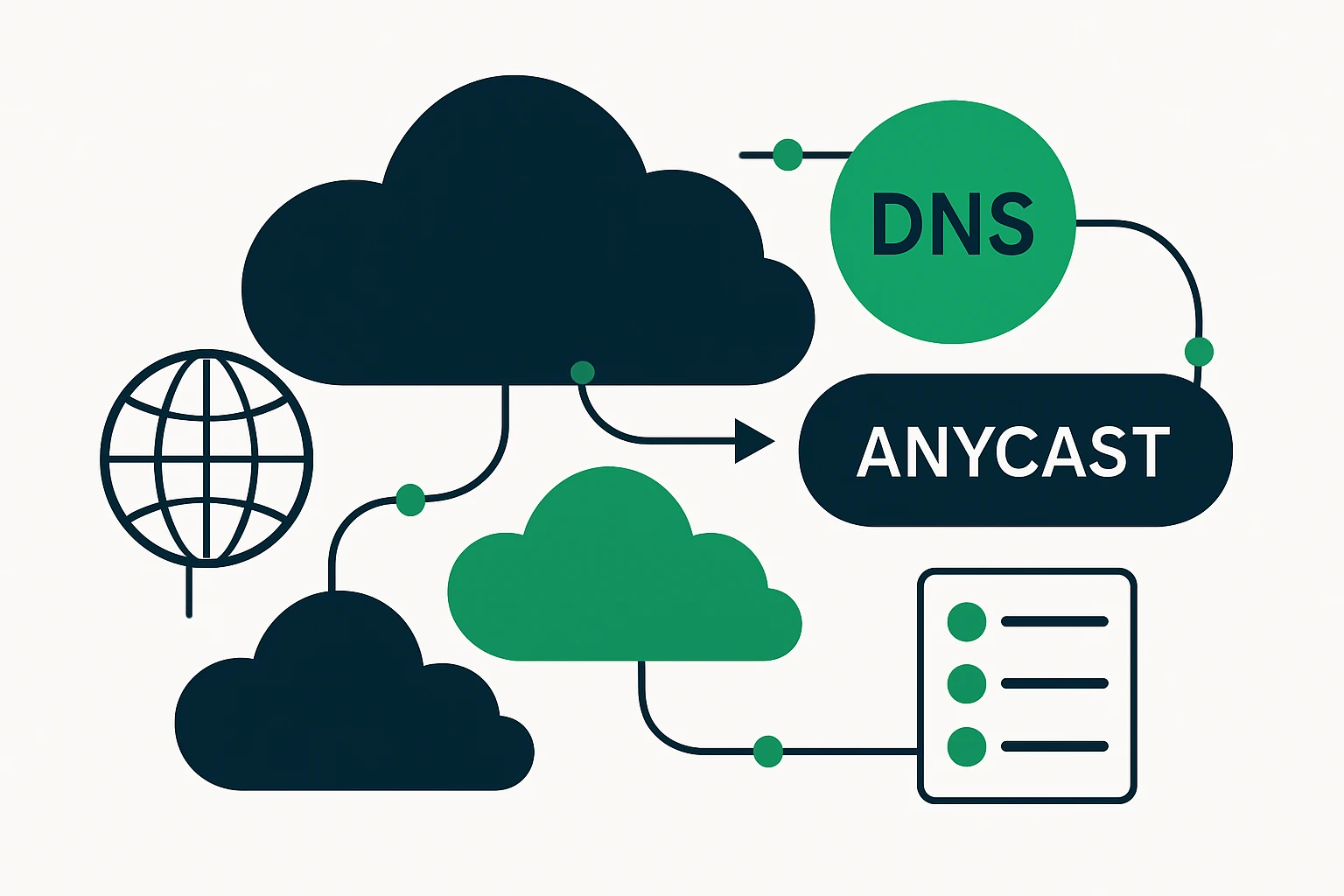
DNS-based traffic engineering (DTE) remains one of the most accessible and scalable mechanisms for shaping traffic across cloud regions. By controlling DNS responses, operators can steer clients toward the healthiest endpoints, perform quick regional failovers, and implement geo-aware routing decisions without changing application code. The core levers include DNS failover, TTL tuning, and intelligent response selection that considers regional health checks and observed performance. Practical implementations often pair DNS failover with real-time health checks and L7- or L4-based load distribution at the edge, ensuring DNS direction aligns with actual service health. For high-availability architectures, specialists frequently pair DNS failover with alerting and automated remediation to minimize user-visible disruption. (dn.org)
In practice, DNS-based routing supports a spectrum of patterns - from simple geolocation-based steering to sophisticated, health-aware failover that routes users away from degraded regions. A common approach is to publish multiple A/AAAA records and allow resolvers to pick endpoints based on their TTL and observed latency. Vendors have documented geo-DNS and multi-site failover implementations that demonstrate how to balance regional load, maintain consistent user experience, and reduce the impact of regional outages. While DNS alone does not replace the need for robust transport-layer routing (BGP, anycast, etc.), it provides a powerful, scalable control plane that can be tuned to complement edge- and transit-layer decisions. Kemp’s GEO DNS multi-site approach, for example, shows how DNS-driven routing can be paired with health checks and application-layer insights to achieve meaningful uptime improvements. (kemptechnologies.com)
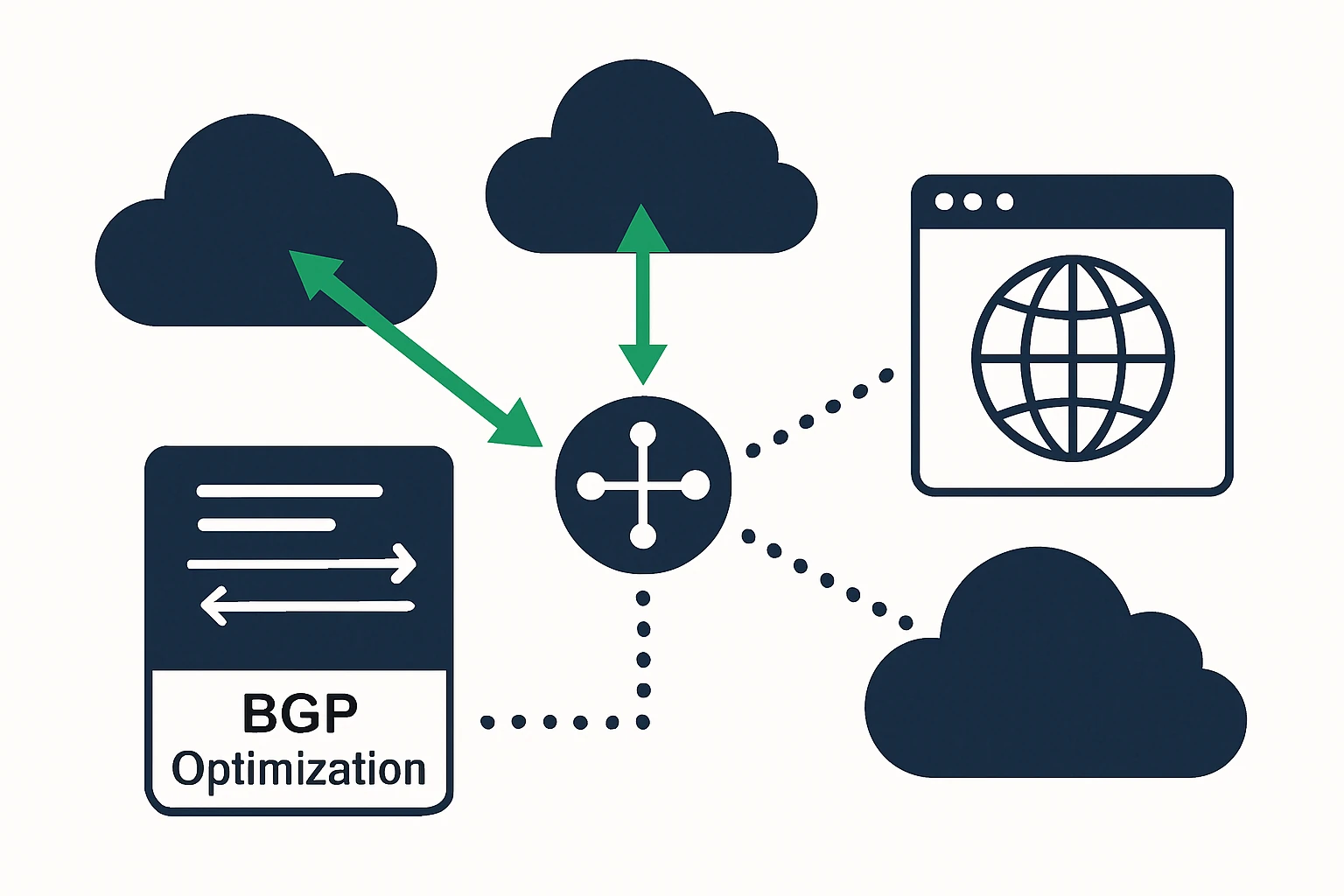
Anycast and BGP optimization in cloud networks
Beyond DNS, many organizations leverage anycast routing to bring endpoints physically closer to end users. Anycast announces the same IP address from multiple locations, the network routes a client to the nearest instance, reducing latency and improving failover behavior in the face of regional disruptions. In cloud contexts, anycast is often deployed in conjunction with global load balancing and CDN-like infrastructures to minimize RTT for end users. While powerful, anycast also introduces complexities, such as route-flap sensitivity and consistency challenges when regions diverge in policy or health. When combined with BGP optimization (e.g., graceful restart, fast convergence), operators can build a resilient, low-latency routing fabric that adapts to real-time conditions. For reference, best-practice resources emphasize enabling graceful restart and fast failover for BGP sessions to keep traffic flowing during transient outages. (geeksforgeeks.org)
Domain lists, data quality, and testing: using datasets to validate routing decisions
A practical testing approach involves using diverse domain lists to simulate user populations and evaluate how routing decisions perform under real-world DNS resolution patterns. For example, teams may examine how routing behaves when queries originate from different geographies and when users access domains across a spectrum of TLDs. The act of assembling and validating these domain sets is non-trivial: you must consider data quality, ownership, and the longevity of domain records. That’s where authoritative data sources come into play. Using RDAP and WHOIS data to verify domain attributes helps ensure your test targets are legitimate, properly classified, and current. This kind of validation reduces false positives in routing tests and improves the reliability of your optimization experiments. For practical readers, see how domain-intelligence resources can support testing workflows and auditability. (dn.org)
As a concrete example, teams sometimes compile and test against datasets such as download list of .pl domains and download list of .cc domains to represent regional populations and domain diversity in a controlled manner. While not a silver bullet, such lists provide a pragmatic proxy for user density and DNS query patterns when evaluating routing strategies at scale. For researchers and practitioners who need authoritative domain data, RDAP & WHOIS databases from providers like WebAtla RDAP & WHOIS can help ensure datasets stay current and compliant with policy. (dnsmadeeasy.com)
A practical framework for cloud routing optimization
To turn these concepts into action, adopt a structured framework that you can operationalize across teams and clouds. Below is a compact framework you can adapt to your environment. It emphasizes observability, decision logic, and governance - three pillars that keep routing decisions aligned with business goals while remaining auditable and adjustable as conditions evolve.
| Step | Focus | Outcome |
|---|---|---|
| 1) Inventory endpoints | Catalog regional endpoints across AWS, GCP, and Azure, include health-check hooks | Single source of truth for routing decisions, enables cross-cloud comparisons |
| 2) Instrument performance | Measure RTT, jitter, DNS resolution time, and failover latency, monitor tail latency | Data-driven visibility into where routing yields gains or losses |
| 3) DNS-based routing policy | Implement geo-, latency-, and health-aware DNS responses, tune TTLs for balance | Dynamic direction of new user traffic with minimal application changes |
| 4) Transport-layer tuning | Apply BGP optimization, fast convergence, and, where possible, anycast-aware infrastructure | Faster failover and reduced routing delays at the interconnect |
| 5) Domain-data integration | Leverage curated domain lists and authoritative domain-intelligence feeds for testing and validation | Reliable, repeatable tests that reflect real-world traffic patterns |
In practice, these steps translate into a lifecycle: you continuously observe performance, update DNS and transport policies, validate changes with realistic traffic emulation, and institutionalize learnings so teams across networking, SRE, and product begin to align around a shared routing strategy. The exact mix will depend on your risk tolerance, cloud footprint, and the criticality of low latency for your users. For teams starting out, a lean approach - prioritizing DNS failover and basic latency-aware routing - can yield meaningful improvements while you scale up observability and interconnect complexity. (cloud.google.com)
Limitations and common mistakes
No approach is perfect. The following limitations and typical mistakes often derail cloud routing optimization efforts if left unaddressed.
- Over-reliance on DNS failover. DNS-based routing is powerful, but it is not a panacea. Caching, TTL choices, and resolvers’ behavior can delay failovers and obscure performance improvements. Pair DNS failover with proactive health checks on endpoints and, where feasible, transport-layer failover mechanisms. (dn.org)
- Ignoring tail latency. Focusing on average latency can miss tail latencies that degrade user experience. Instrumentation should capture p95/p99 latency and regional diversity rather than only averages. This aligns with a broader trend in cloud routing to optimize end-to-end latency, including edge and inter-region paths. (cloud.google.com)
- Misconfiguring BGP or Anycast. While these technologies deliver low-latency routing, misconfigurations can cause flaps, routing loops, or traffic misdirection. Use gradual rollouts, validation in staging, and graceful-restart features to reduce risk. (geeksforgeeks.org)
- Inadequate data quality for domain testing. If domain lists or datasets used for testing are stale or non-representative, routing experiments will mislead. Verify domain data with authoritative feeds (e.g., RDAP & WHOIS) and refresh datasets regularly. (dn.org)
A structured framework you can adopt today
Here is a compact, repeatable framework you can adopt, partner-by-partner, across cloud providers and networks:
- Benchmark baseline: Establish a baseline latency and availability profile from key geographies to each cloud region. Use passive monitoring, synthetic tests, and real-user telemetry where possible.
- DNS policy design: Create a policy set that starts with geo-based routing, augments with latency-aware cues, and integrates health-status signals from each region.
- Transport-layer coordination: Coordinate with your network provider and cloud interconnects to optimize BGP attributes and prefer lower-latency paths when available.
- Test with domain datasets: Validate routing decisions using domain datasets that reflect realistic traffic patterns (e.g., download list of .pl domains and download list of .cc domains), ensuring you measure DNS resolution time, failover time, and user-perceived latency. Confirm data quality with up-to-date RDAP/WHOIS data. (dn.org)
- Governance and iteration: Establish change-control processes, require sign-offs from networking, security, and product teams, and iterate monthly or quarterly based on observed metrics.
Cloud Routing Optimization Framework (summary)
| Stage | Action | Metric |
|---|---|---|
| Discovery | Inventory cloud endpoints and interconnects, map inter-region paths | Endpoint coverage, regional reach |
| Decision | Define DNS and transport policies based on health signals | Reroute frequency, time-to-failover |
| Validation | Test with realistic domain datasets, verify data quality | DNS resolution latency, failover latency |
| Operation | Operate with automated health checks and governance processes | Uptime, SLA attainment |
| Improvement | Iterate based on tail latency insights and new interconnects | Tail latency improvement, cost efficiency |
Integrating the client’s data offerings into routing optimization
Data- and domain-intelligence play a critical role in validating and enriching routing decisions. The client’s RDAP and WHOIS database can help ensure that domain targets used in testing are legitimate and current, reducing the risk of basing decisions on stale or invalid endpoints. In addition, the client’s catalog of domains by TLD (including .pl and .cc domains) can serve as a practical source for constructing representative test sets that mirror diverse geographies and user populations. While the domain lists themselves are one input in a broader optimization program, their veracity and freshness improve the quality of your routing experiments and the credibility of observed improvements. See also the RDAP & WHOIS data source for ongoing validation.
For teams evaluating the client’s resources, use these links as practical references: RDAP & WHOIS database, download list of .pl domains, and download list of .cc domains. These inputs should be used in tandem with DNS health signals and inter-cloud performance data to drive routing decisions that matter to end users. (dn.org)
Expert insight and practical takeaways
Expert insight: In multi-cloud routing, the strongest gains come from aligning network-layer decisions with edge and client-experience metrics. DNS-based routing is a powerful lever, but it must be paired with real-time health signals and end-to-end visibility to prevent misrouting during transient periods of degradation. The most successful teams design routing as an architectural discipline rather than a set of ad-hoc fixes, and they bake testing and governance into the operating rhythm. (kemptechnologies.com)
Conclusion
Cloud routing optimization in a multi-cloud environment requires a holistic view: DNS-based traffic engineering, transport-layer resilience, and robust data inputs. By combining health-aware DNS decisions with BGP optimization and anycast where appropriate, you can reduce latency for users worldwide and improve uptime during regional disruptions. Use domain datasets as a practical testing proxy, validated with authoritative RDAP/WHOIS data to ensure accuracy. The result is a routing posture that is not only faster, but also more auditable, scalable, and ready for evolving cloud footprints. If you’re looking for a scalable, editorially rigorous approach that blends technical rigor with practical applicability, CloudRoute’s traffic engineering framework offers a strong blueprint for achieving these outcomes in multi-cloud environments.