Introduction
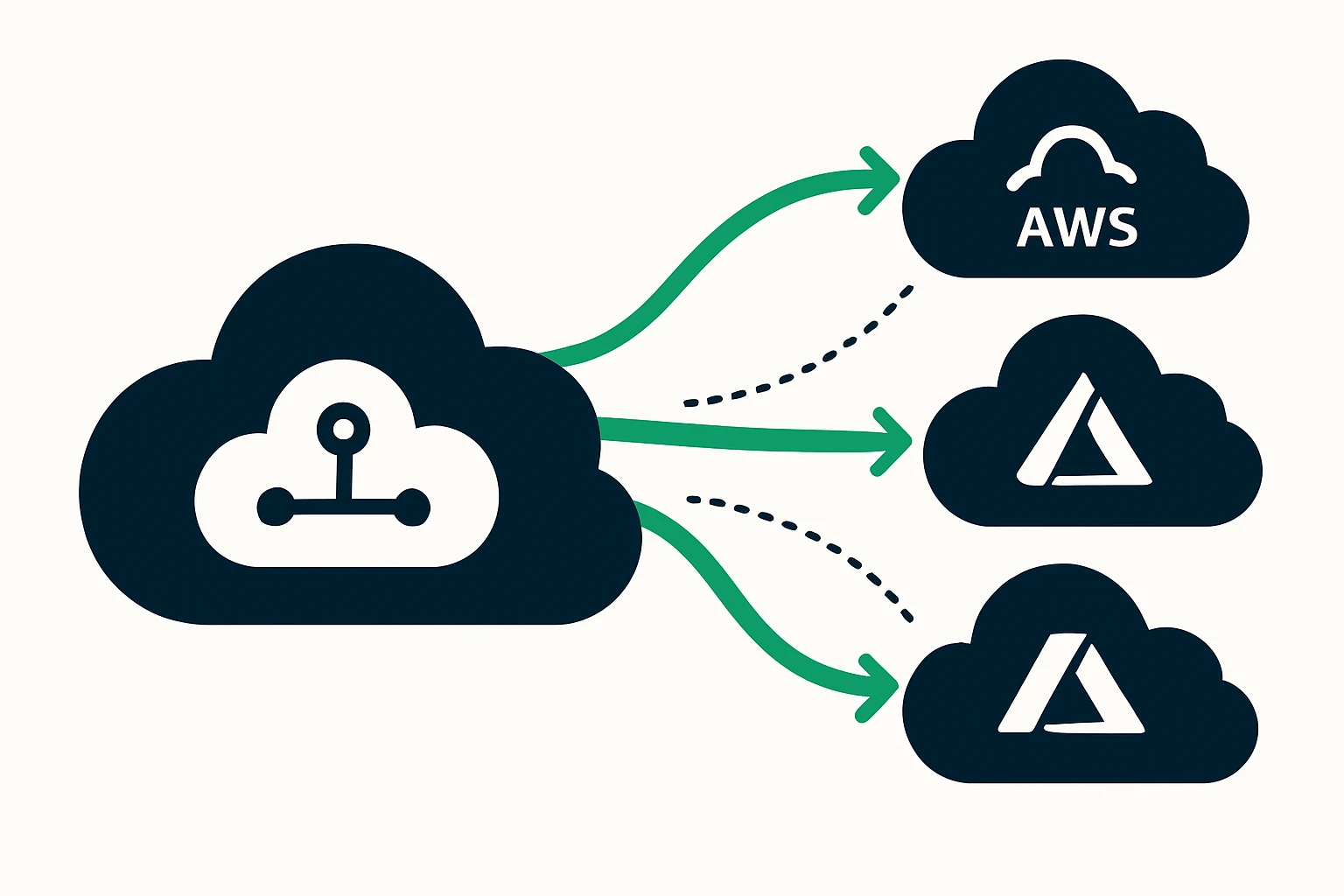
As enterprises push applications to run across multiple cloud providers - most commonly AWS, Google Cloud, and Azure - the network path from end users to services becomes as important as the services themselves. Latency, jitter, and occasional outages are not merely IT concerns, they translate directly into user experience, conversion rates, and uptime commitments. The challenge is not just to deploy in a multi-cloud footprint, but to route traffic intelligently across regions and providers in real time. This is where cloud routing optimization, traffic engineering, and geo-aware DNS play a pivotal role. By aligning routing choices with user proximity, health checks, and provider capabilities, teams can reduce end-user latency while preserving resilience across the cloud edge. Google Cloud: Cloud Router best practices provide concrete guidance for BGP health checks and failover readiness, while Geo DNS can dramatically improve latency and availability by steering clients to the nearest regional endpoint. AWS Route 53 best practices outline how to balance rapid failover with predictable performance.
Foundations of cloud routing optimization
In multi-cloud architectures, routing decisions are driven by three core ideas: proximity, availability, and capacity. Proximity ensures users are served from the closest data plane to minimize distance and hops. Availability requires frequent health checks and fast rerouting when an endpoint becomes unhealthy. Capacity involves selecting paths or endpoints that can absorb traffic without creating bottlenecks elsewhere in the network. While applications concentrate on code and data, the network team concentrates on where requests travel and how quickly they arrive. Practical routing strategies include:
- Geographic or proximity-based routing to direct clients to nearby PoPs or edge locations.
- Health-aware routing that redirects traffic away from failed or degraded paths.
- Cross-cloud awareness so failover occurs not only within a single provider but across providers when beneficial.
Geo-aware routing is particularly impactful in multi-region deployments. By directing traffic to the closest healthy endpoint, latency is reduced and user experience improves. For a deeper dive into Geo DNS and its impact on latency, see the Geo DNS overview from Gcore. What is Geo DNS?
Geo-DNS and DNS failover: steering latency and uptime across clouds
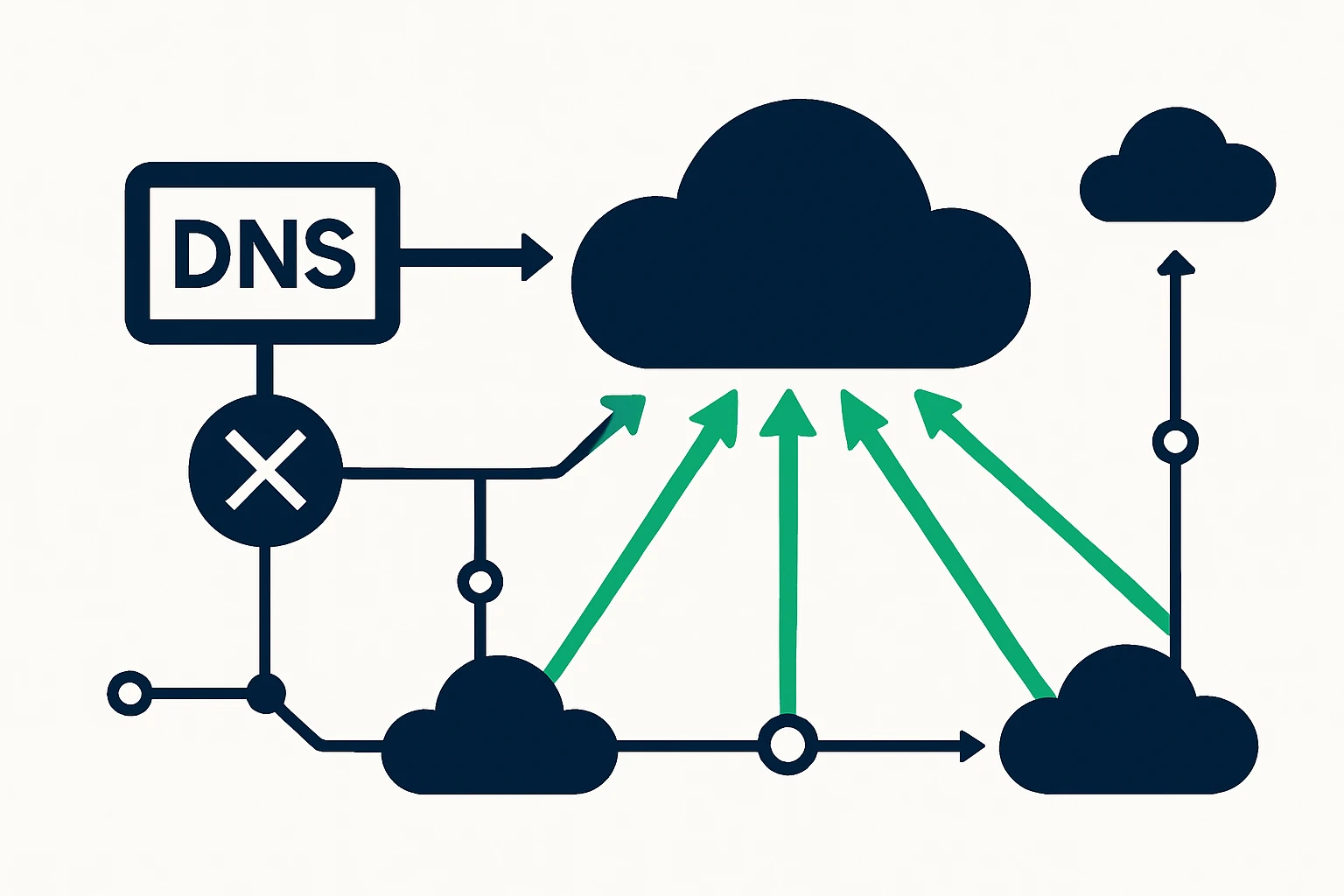
Geo-DNS, sometimes called geographic DNS routing, maps a user’s location to the nearest available service endpoint. In multi-cloud scenarios, this means directing traffic to the closest regional cloud instance, reducing round-trip times and improving the perceived responsiveness of web and API services. The approach is especially valuable when you have regional data sovereignty requirements or when some cloud regions are under heavy load while others are underutilized. A modern Geo DNS strategy benefits from dynamic ECS (EDNS Client Subnet) to improve locality awareness, but must be balanced with privacy and caching considerations. See the Geo DNS overview by Gcore for a practical discussion of latency gains and routing accuracy.
DNS failover is a complementary technique that helps maintain availability during regional outages or provider-specific issues. The core concept is to monitor service health and quickly switch resolution to alternate endpoints. A common implementation uses DNS health checks and low DNS TTLs to shorten failover windows, while balancing DNS query load and cache behavior. For an authoritative treatment of DNS failover best practices and TTL considerations, refer to AWS Route 53 best practices. This guidance emphasizes health checks, weighted routing, and geolocation routing alongside prudent TTL choices to manage failover responsiveness.
From a practical perspective, many organizations adopt a layered approach: geo-routing to reduce latency, health-based routing for reliability, and cross-region and cross-cloud failover to preserve uptime when a single cloud region experiences issues. Implementations typically involve at least two cloud providers and a DNS strategy that can direct a user to the best available endpoint in real time. The result is a more predictable user experience even under imperfect network conditions.
A practical framework for traffic engineering across clouds
To operationalize cloud routing optimization in a real-world environment, consider a structured, repeatable framework. The following six-step approach integrates routing decisions with observability and domain strategy to deliver measurable latency and reliability gains across AWS, GCP, and Azure.
- Map workloads to optimal locations: Catalogue where your users are and where your services run. Identify edge locations and cross-cloud interconnects that can serve as preferred endpoints for major user populations.
- Instrument latency and health across regions: Collect real-time round-trip times, regional s QoS, and endpoint health metrics. Consistent health signals enable rapid rerouting when conditions change.
- Adopt geo-aware routing for user proximity: Implement Geo DNS or geo-based routing to steer new sessions to the closest healthy region or data center, balancing latency and capacity constraints.
- Implement cross-cloud, health-driven failover: Design failover policies that can switch endpoints not only within a provider but across providers when it yields lower latency or higher reliability.
- Polish DNS failover with prudent TTLs: Use short TTLs for critical records to speed failover, but manage query volume and cache behavior to avoid DNS storms. AWS Route 53 guidance provides concrete TTL considerations for fast yet stable failover.
- Continuous validation and tuning: Treat traffic routing as an evolving control loop. Regularly retrain routing choices based on evolving user geography, performance data, and cloud-region capacity.
Structured practice is essential to avoid common misconfigurations and to ensure the approach scales as you add regions and cloud providers. For readers seeking an explicit, vendor-agnostic playbook, the framework above offers a practical path to improved latency and resilience in multi-cloud environments. For a deeper understanding of routing best practices in cloud networks, the guidance from Google Cloud on Cloud Router and health checks is a solid reference, and AWS Route 53 best practices illustrate how to combine health checks with routing policies.
In parallel with routing decisions, an effective domain data strategy can support both security and performance objectives. For example, specialized domain lists (e.g., .ma, .fyi, .ovh) and bulk domain catalogs are often used by security and network teams to monitor or gate traffic at the edge. See the the .ma domain list as an example of a domain catalog, or explore the broader list of domains by TLD for additional context. You can also leverage RDAP and WHOIS data to enrich domain intelligence: RDAP & WHOIS data.
Limitations, trade-offs, and common mistakes
No routing strategy is free of compromises. Below are the most frequent pitfalls and how to avoid them:
- Over-reliance on TTLs: While short TTLs speed failover, they increase DNS query load and can overwhelm authoritative servers if not managed carefully. Strike a balance between responsiveness and query volume.
- Ignoring user geolocation nuances: Geo routing can improve latency, but misconfigurations or stale location data can misdirect users. Regularly refresh geolocation mappings and review ECS privacy considerations.
- Uncoordinated multi-cloud traffic paths: Static routing in multi-cloud environments can create hairpinning or suboptimal paths. Introduce health-checked, cross-cloud routing that adapts to capacity changes.
- Underestimating inter-region latency variability: Latency is not uniform across regions, performance budgets should reflect regional variations to avoid overloading remote paths during peak demand.
- Misconfiguring health checks: Inadequate health checks can cause premature failovers or oscillations. Align health-check cadence with application SLA and user experience requirements.
Expert insight: enterprises pursuing high availability in multi-cloud networking commonly combine proximity-based routing, health checks, and cross-provider failover to preserve latency and uptime. The practical literature on cloud routing emphasizes the need for health-aware routing and disciplined TTL management as part of a broader resilience strategy.
Domain data and edge routing: a practical note for operators
Beyond transport routing, domain data strategy can influence edge decisions and security postures. Bulk domain catalogs - such as lists for specific TLDs - are often used in governance, threat intelligence, or domain-based allowlists. For example, the .ma domain catalog is available for targeted use in edge policies, while broader lists by TLDs can support governance across cloud regions. See the the .ma domain list, and the list of domains by TLD for reference. For domain data enrichment, the RDAP & WHOIS database provides programmatic access to domain metadata.
Structured takeaway: a quick-reference framework
Here is a compact framework you can apply when planning or auditing a multi-cloud routing strategy. Use this as a quick-start checklist or a basis for a formal policy document.
- Define primary user geographies and service regions
- Establish Geo DNS routing rules to minimize distance to users
- Set up health checks across cloud regions and providers
- Configure cross-cloud failover with appropriate TTLs
- Monitor performance and iterate routing policies quarterly
Conclusion
In multi-cloud environments, latency and reliability hinge on intelligent routing as much as on the services themselves. By combining geo-aware routing with health-driven failover, and by treating DNS behavior as a first-class control plane, organizations can reduce latency for global users while maintaining strong resilience against regional disruptions. The practical guidance from cloud providers and DNS specialists supports an approach that is both vendor-aware and platform-agnostic in spirit: route to the best available endpoint, monitor continuously, and tune decisions as your user base and cloud footprint evolve. If you are evaluating domain catalogs as part of edge policy or threat intelligence, consider how district-domain data can support routing decisions and security postures. For reference on bulk domain datasets, you can explore the .ma and other TLD lists linked above.
Further reading and sources
- Cloud Router best practices: Google Cloud
- Geo DNS and latency: Gcore Geo DNS
- DNS failover and routing best practices: AWS Route 53
Related concepts: anycast routing, bgp optimization, geo DNS routing, dns failover strategies, latency reduction, multi-cloud networking, edge routing, health checks, load balancing strategies, traffic telemetry
Edge policy and domain data decisions can benefit from concrete domain catalogs. For example, see the .ma domain list at the .ma domain list, the broader list of domains by TLD, and the RDAP/WHOIS catalog at RDAP & WHOIS data.