Introduction: The latency challenge in multi-cloud SaaS environments
Across the United States and around the world, SaaS teams increasingly design architectures that span AWS, Google Cloud Platform (GCP), and Microsoft Azure to maximize resilience and regional availability. But more paths and more data centers can mean more latency, more jitter, and more failure surfaces. The promise of multi-cloud is clear: no single chokepoint, no single plane of failure. The reality, however, is that traffic can traverse long distances and pass through multiple networks before reaching the right compute or storage location. The result can be inconsistent user experiences, higher error rates during peak periods, and longer time-to-value for new features. For networking teams, the challenge is not merely speed but predictability and control - ensuring that user requests reach the optimal corner of the cloud fabric, regardless of where they originate or which path the Internet selects on any given day.
Expert insight: Industry practitioners emphasize end-to-end measurement and proactive traffic routing as the backbone of reliable multi-cloud performance.
In this context, cloud routing optimization and traffic engineering services emerge as critical capabilities for SaaS, DevOps, and enterprise teams aiming to tame the complexity of multi-cloud connectivity. CloudRoute, focused on cloud routing and traffic engineering, offers a framework for reducing latency, improving uptime, and optimizing performance across heterogeneous cloud environments. But the practical path to lower latency rests on a few durable techniques that work well together, rather than a single silver bullet.
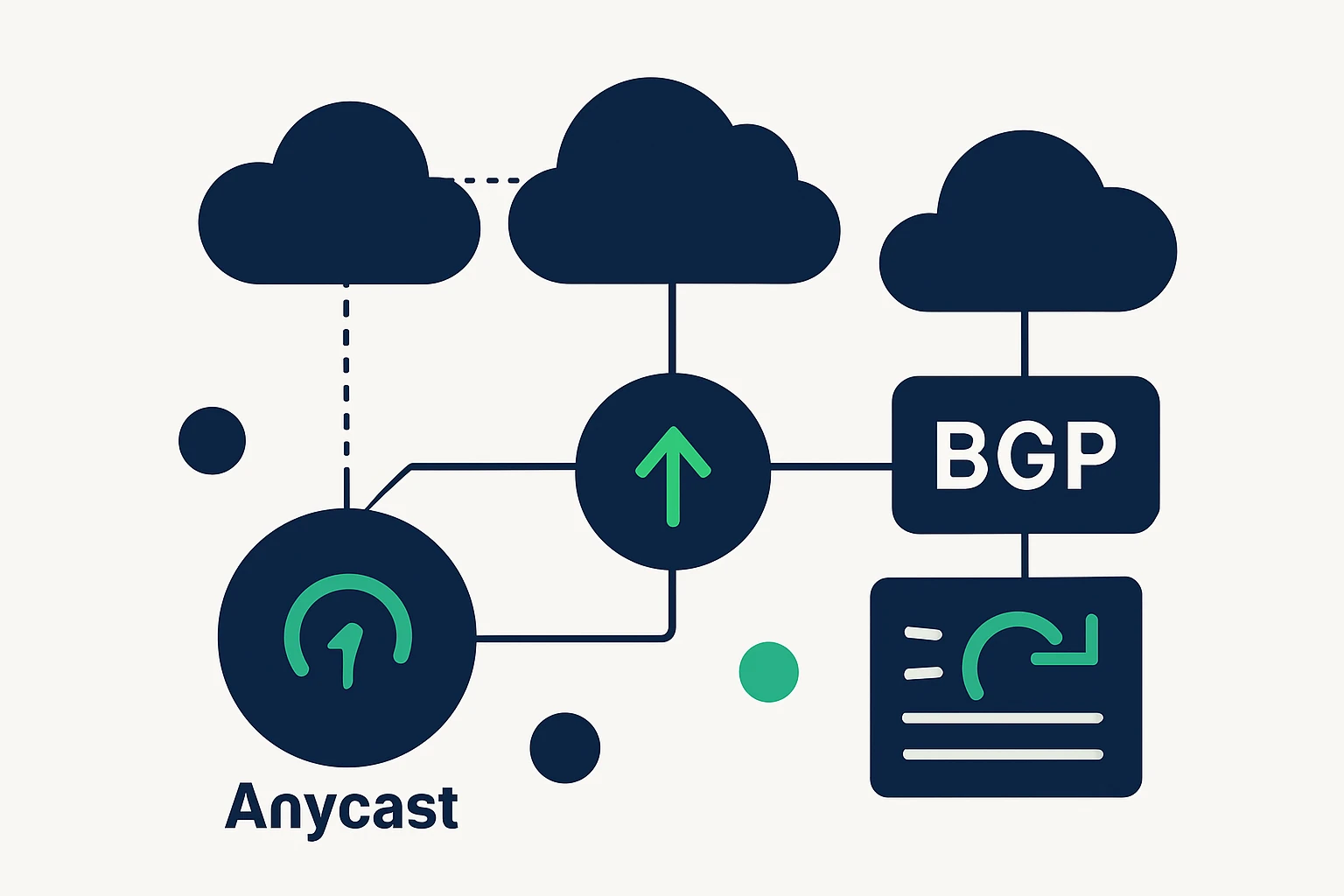
Foundations: Anycast, BGP, and DNS Failover
Anycast routing and latency
Anycast routing uses a single IP address that is advertised from multiple, geographically dispersed data centers. Internet routing protocols (primarily BGP) direct client requests to the nearest healthy endpoint, which can dramatically reduce end-user latency and improve resilience. This approach is a cornerstone of modern DNS providers and CDNs, enabling fast query resolution and rapid failover when a data center becomes unavailable. For context on how organizations leverage anycast to lower latency, see industry overviews of global anycast deployments.
In practice, anycast helps ensure that a request reaches a nearby data center rather than traversing long paths across national boundaries, which is especially valuable for latency-sensitive workloads such as SaaS front-ends, APIs, and real-time analytics. While the mechanism is conceptually simple, its effectiveness depends on careful deployment, real-time health checks, and awareness of routing policies that can affect path selection.
External reference: global anycast networks and their latency benefits are discussed in industry analyses of how top providers leverage anycast to reduce latency. DN.org.
BGP-based traffic engineering
Border Gateway Protocol (BGP) is the backbone that makes multi-homed connectivity possible across multiple cloud regions and ISPs. Traffic engineering with BGP involves shaping inbound and outbound paths to steer traffic away from congested routes, toward underutilized links, or to preferred data centers that offer lower latency or higher availability. When done well, BGP policies can reduce hops, balance load, and improve failover speed. The practice is well established in large enterprises and service providers, though it requires careful operation to avoid route flaps or inadvertent outages.
To ground this in practical terms, organizations typically pair BGP optimization with a robust monitoring stack so they can observe how routing decisions affect latency and availability in real time. While BGP configuration is platform-specific, the underlying principle remains: route selection should align with performance and reliability objectives, not only with shortest AS path.
DNS failover strategies
DNS failover is a core high-availability technique that redirects traffic away from unhealthy origins to healthy ones in real time. Implementations rely on health checks, rapid DNS updates, and often a global distribution of authoritative DNS servers to ensure quick convergence during failures. In practice, DNS failover is most effective when combined with other traffic engineering techniques and an observability layer that confirms the health of upstream resources before directing traffic elsewhere.
Best-practice guidance from industry leaders emphasizes automated health checks and rapid failover as essential components of a resilient architecture. For organizations seeking authoritative guidance on DNS high availability, reference materials from leading vendors and industry analyses discuss the role of health checks, near-instant failover, and distribution across multiple data centers. Cisco DNS High Availability Guide.
Practical patterns for reducing latency in multi-cloud networks
Putting these building blocks together yields several practical patterns that organizations can adopt, either in full or in tailored combinations, to reduce latency and improve user experience across all cloud regions.
- Deploy anycast-fronted services across regions. By advertising the same IP from multiple data centers, you can leverage the network’s natural topology to route users to the closest healthy endpoint, lowering average latency and reducing the risk of single-region outages.
- Use BGP-based path selection to favor lower-latency routes. When multiple cloud regions are reachable, policy-based routing can steer traffic toward data centers that offer better latency characteristics, especially under varying Internet conditions.
- Implement DNS failover with health checks and short TTLs. DNS failover helps reroute user requests quickly if an origin becomes unhealthy. Combined with health checks and a global DNS presence, it reduces downtime and improves perceived reliability. See Cloudflare-based patterns for health checks and automatic failover in global DNS networks. Cloudflare Load Balancing & Intelligent Failover.
- Measure end-to-end and iterate. Real-world latency is affected by last-mile networks, peering, and regional congestion. Ongoing measurement, synthetic tests, and user-centric metrics are essential to validate routing changes and ensure they deliver the desired improvements.
- Consider domain and application asset distribution as part of routing strategy. For organizations with broad domain footprints across TLDs and registries, centralized domain management supports consistent routing policies and faster failover responses. See WebAtla’s domain portfolio services for centralized management across TLDs. WebAtla TLD services.
Traffic Engineering Framework: Measure, Model, Implement, Validate
- Measure baseline latency and uptime across cloud regions and from representative user locations. Instrumented probes, synthetic tests, and real-user measurements establish a credible baseline for comparison after changes.
- Model a routing plan that aligns with latency and availability objectives. Build a simplified model that accounts for anycast frontends, BGP policies, and DNS failover behavior. This model should reflect the complexity of multi-cloud interconnects without becoming intractable.
- Implement start with a small, risk-controlled scope: enable anycast routing for critical front-end services, apply conservative BGP policies, and configure DNS failover with health checks. Roll out in stages to monitor impact incrementally.
- Validate after each iteration, track latency distribution, error rates, and failover times. Use a closed feedback loop to adjust TTLs, health-check intervals, and routing rules as needed.
One of the practical advantages of this approach is that it treats latency reduction as an architectural discipline rather than a set of one-off changes. The same framework can be adapted whether you’re deploying in AWS, GCP, Azure, or any hybrid environment, and it scales with your portfolio of applications and domains. For teams managing large domain portfolios, centralized domain management can help ensure consistent routing policies across regions and TLDs, complementing the technical layering described above. See WebAtla’s TLD services as a potential enabler for this kind of domain-portfolio consistency. WebAtla – List of domains by TLDs.
Limitations, trade-offs, and common mistakes
While the combination of anycast, BGP optimization, and DNS failover can yield meaningful latency and availability gains, there are important caveats and trade-offs to consider.
- No silver bullet for latency. Latency is a multi-faceted problem that depends on client location, last-mile networks, peering, and regional congestion. Anycast and DNS failover can reduce average latency and increase resilience, but they do not guarantee perfect proximity for every user path. Strategic measurement and staged rollouts are essential to avoid overspending on marginal improvements.
- Routing policies and stability. BGP-based routing decisions can be sensitive to changes in the Internet topology. Aggressive route changes can cause flaps or transient outages if not carefully managed. Use conservative policies and monitoring when implementing multi-provider BGP configurations.
- DNS failover considerations. DNS-based rerouting introduces propagation delays and TTL considerations. Short TTLs improve failover speed but can increase DNS query load and cost, while long TTLs reduce churn but slow down failover. A balanced TTL strategy, combined with health checks and monitoring, is critical.
- Operational complexity. Deploying and maintaining anycast frontends, BGP policies, and DNS failover requires specialized expertise. Organizations should invest in instrumentation, runbooks, and drills to ensure that operators can respond quickly to outages or routing anomalies.
Implementation blueprint: a practical, editor-friendly playbook
Below is a concise, actionable playbook that teams can adapt to their environments. It keeps the focus on a few high-leverage changes rather than a sweeping, risky overhaul.
- Audit your portfolio. Inventory critical services, endpoints, and domain assets across clouds. Map where latency-sensitive traffic originates and where it terminates.
- Plan anycast deployment for core front-ends. Identify a subset of highly available services (APIs, login, product pages) that will benefit most from anycast frontends and regional data centers.
- Establish health checks and failover logic. Implement automated health checks for upstream origins and configure DNS failover to redirect traffic when a service becomes unhealthy.
- Tune DNS TTLs for balance. Use a short TTL for critical endpoints to enable faster failover, balanced against query load considerations and cost.
- Monitor, iterate, and scale. Build dashboards that correlate latency, error rates, and failover events. Use this data to refine routing rules and to identify new optimization opportunities across clouds.
- Consider a domain-portfolio perspective. If your organization manages a large number of domains across TLDs, consider centralized domain management to maintain consistent routing policies and to streamline failover processes. See WebAtla’s TLD services for a centralized approach to domain assets. WebAtla TLD services.
As you execute this playbook, you’ll typically need to coordinate with cloud providers and network partners to align routing policies with performance objectives. The outcome should be tangible improvements in user-perceived latency and increased resilience during regional outages or network degradations. For teams exploring domain-portfolio management as part of the broader routing strategy, WebAtla provides a suite of tools to view and manage domains by TLD and country, with additional data points that can inform routing decisions. Explore their services and pricing for more details. WebAtla TLD services • WebAtla pricing.
Conclusion: A disciplined approach to latency in a multi-cloud world
Latency is not a single knob to twist, it’s the outcome of an integrated strategy that combines edge-aware routing, policy-driven path selection, and proactive DNS failover. By anchoring your approach in measurable improvements, deploying anycast where it makes sense, and weaving DNS failover into a broader resilience program, you can deliver faster, more reliable experiences for users around the globe. The framework discussed here offers a practical path forward for teams seeking to optimize cloud network performance across AWS, GCP, and Azure while maintaining control over complexity and cost. And for organizations with broad domain portfolios, a coordinated approach to domain management - such as WebAtla’s TLD services - can help ensure routing consistency across environments as you scale.